背景
为理解 web 页面解析的过程,总结其中涉及的基础知识和可能存在的安全问题。
WEB 页面解析的总体流程
客户端(浏览器)发起页面请求,主机对 地址中的DNS 域名进行解析,找到对应的 IP 地址,请求发送到 服务端,服务器根据请求内容发送响应给客户端,客户端收到响应,将内容渲染成网页。
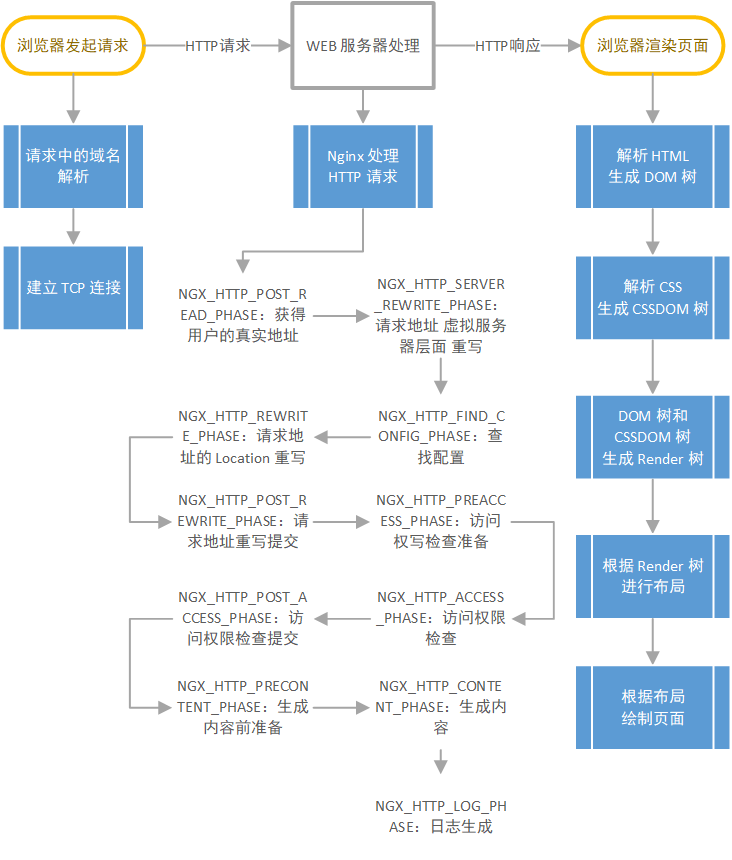
DNS 基础
DNS(Domain Name System),即域名解析系统,用于为网络中的主机提供容易记忆、便于阅读的名字。网络主机虽然可以通过 IP 地址标识,但是在我们的日常生活中,我们当然更喜欢容易阅读的域名来标识一个主机,如 www.baidu.com 而不是一连串类似 183.232.231.174 的一串数字,但是域名无法被网络层的设备如路由器等识别,还需要转换成相应的 IP 地址,这就需要 DNS 提供这项服务。DNS 包含一个分布式、分层级的服务器组,用于提供将域名转换成 IP 地址的服务,另外还提供如何完成这一服务的协议;DNS 协议基于 UDP 进行通信,端口号为 53。
DNS 服务器的分层结构
DNS 服务器采用分布式、分层的方式部署在世界各地。按照层级从高到低,DNS 服务器分为:根域名服务器(Root DNS Servers)、顶级域名服务器(TLD DNS Servers)、权威域名服务器(Authoritative DNS Servers),层级关系如下图:
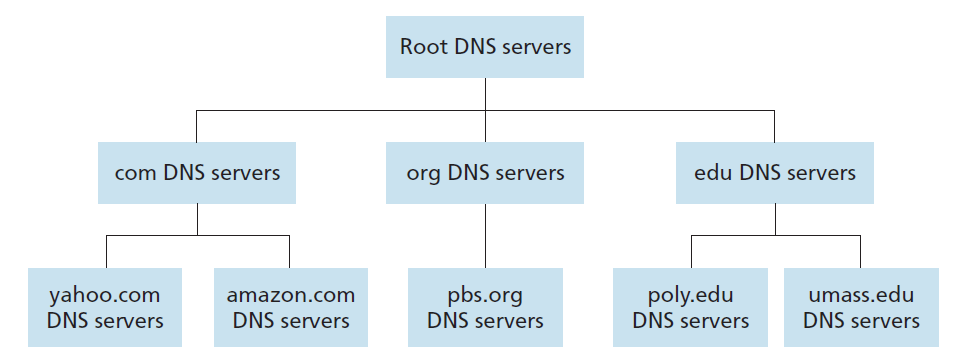
根域名服务器:世界上有 13 个根域名服务器,准确来说是 13 组服务器群组,服务器组中的每一个根域名服务器都有所有顶级域名服务器(com, org, gov …)的 IP 地址。顶级域名服务器:为顶级域名如 com、org、net 等提供域名解析服务,每一个顶级域名都有相应的顶级域名服务器,存放其所有子域名的 IP 地址。权威域名服务器:各种组织机构,如企业、学校、政府组织等都需为其提供网络服务的主机取一个合适的域名,如 百度公司的 baidu.com,而主机的 IP 地址和域名的对应关系就保存至其权威域名服务器中。一般大公司和学校都会部署自己的权威域名服务器。
域名解析流程
DNS 域名解析服务的总体流程如下图,查询主机需要知道 cis.poly.edu 的 IP 地址,按照图中的顺序依次进行域名解析。
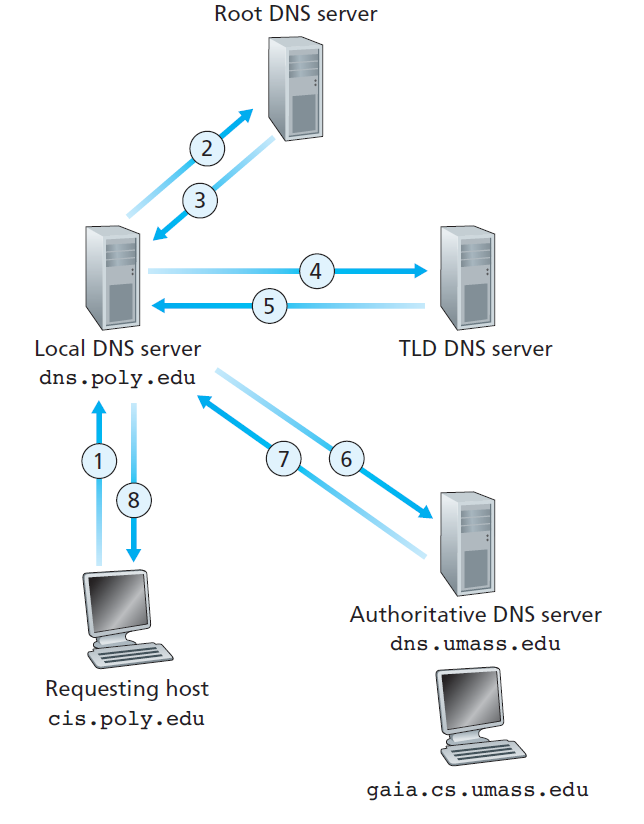
以使用浏览器访问 www.baidu.com 为例,域名解析过程大致如下:
- 主机上的域名解析:浏览器首先查看浏览器中的缓存是否缓存了 www.baidu.com 的 IP 地址,如果存在则直接使用,不存在则在主机中的 DNS缓存 和 hosts 文件查找,如果存在则直接使用。
- 本地域名服务器上的解析:当在主机无法自己完成域名解析时,进一步向
本地域名服务器询问域名 www.baidu.com 的 IP 地址,本地域名服务器首先会查看服务器上的 DNS 缓存,如果存在相应的缓存则返回给查询主机,反之则进一步向根域名服务器发起一个域名解析请求。本地域名服务器一般都是我们接入的网络的管理机构提供,如我们一般在家里都是用网络服务提供商(电信、移动、联通等)提供的网络接入服务,相应的本地域名服务器也由各个ISP提供,而当我们接入校园网时,则由学校提供。 - 根域名服务器上的解析:当根域名接收到
本地域名解析服务器发起的域名解析请求后,根域名服务器返回 www.baidu.com 的顶级域名com的一个或多个 IP 地址,因为根域名服务器只负顶级域名的解析。 - 顶级域名服务器上的解析: 当
本地域名服务器收到顶级域名com的IP地址后,进一步com的域名服务器发起一个域名解析请求,顶级域名服务器返回可以解析 www.baidu.com 的一个权威域名服务器地址。 - 权威域名服务器上的解析: 当
本地域名服务器收到 www.baidu.com 的权威域名服务器的地址后,进一步向权威域名服务器发起对 www.baidu.com 的域名解析请求,该权威域名服务器收到请求后,返回 www.baidu.com 的 IP 地址和 有效时间TTL给本地域名服务器。 - 本地域名服务器上完成解析:
本地域名服务器收到 www.baidu.com 的 IP 地址,放到服务器的 DNS 缓存中,设置缓存的TTL,标识该 DNS记录的有效时间,最后返回 www.baidu.com的 IP 地址给查询主机。
最终主机获得 www.baidu.com 的 IP 地址,并将本次查询的 DNS 记录缓存系统中的 DNS 缓存中,同样设置相应的TTL。
HTTP 协议基础
HTTP (HyperText Transfer Protocal,超文本传输协议) 是应用层协议,使用 TCP 协议进行数据传输,常用端口号为 80,用于实现 Web 客户端 和 Web 服务器之间的通信。HTTP 协议规定了客户端和服务端之间通信的报文格式以及数据交换的流程。
HTTP 报文格式
HTTP 报文分为客户端发送的请求报文和服务端发送的响应报文,用于建立通信和数据传输。
HTTP 请求报文格式
HTTP 请求报文由三部分组成:
- 请求行(Request line),声明请求方法、请求资源的URL路径、HTTP 版本号
- 首部行(Header line),声明额外的信息,
- 实体主体(Entity Body),存放需要传输的数据
请求行和首部行,每行都以 回车(carriage return,cr)和换行符 (line feed,lf)结尾。
首部行和实体主体之间有一空行,同样以回车和换行符结尾。
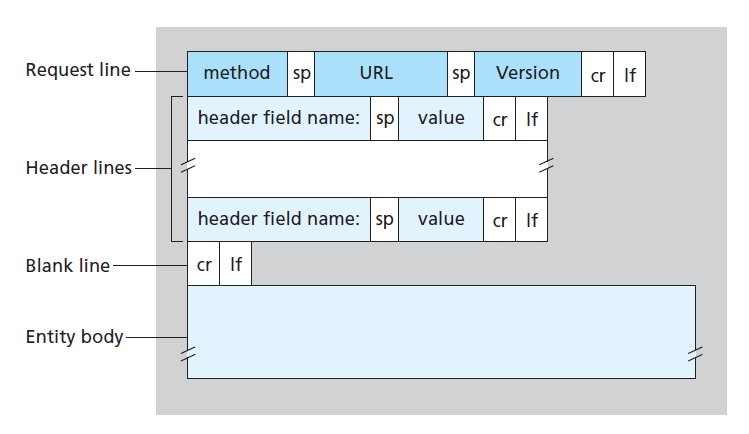
一个简单示例:
1 | GET /somedir/page.html HTTP/1.1 |
HTTP 响应报文格式
HTTP 响应报文的格式和请求报文格式类似,也由三部分组成:
- 状态行(Status line),声明 HTTP 的版本号,响应的状态码和相应的状态消息
- 首部行(Header line),声明额外信息
- 实体主体(Entity body),存放需要传输的数据
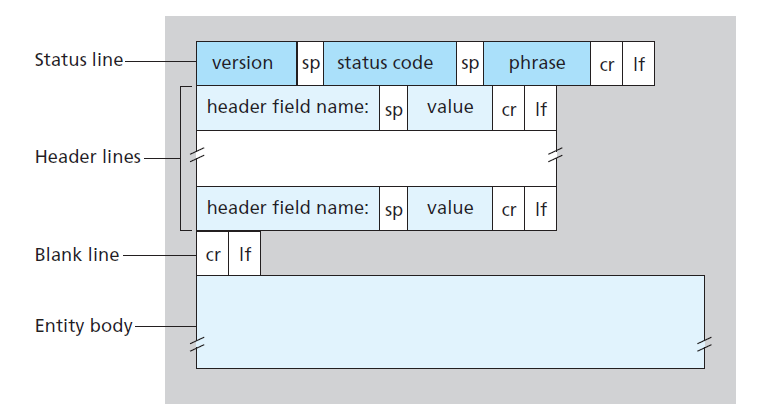
一个简单示例:
1 | HTTP/1.1 200 OK |
HTTP 请求方法
现有的 HTTP 请求方法共有 9 种,包括由 HTTP1.0 定义的 GET、HEAD 、POST 三种方法 和在 HTTP1.1 版本中新增的 PUT、DELETE、CONNECT、OPTIONS、TRACE 和 PATCH 6种方法。
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回消息主体。 |
| 2 | HEAD | 类似于 GET 请求,只不过返回的响应中没有消息主体,仅获取报文的头部(状态行+首部行) |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在消息实体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | DELETE | 请求服务器删除指定的资源。 |
| 6 | CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| 9 | PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 |
HTTP 首部字段
HTTP 首部字段用于定义客户端和服务端通信的额外信息,按照首部的使用条件可分为四类:
- 通用首部,可用于请求和响应报文中,和实体主体无关;
- 请求首部,仅用于请求报文中,存放请求的详细信息,如请求资源的要求、请求主机的信息等;
- 响应首部,仅用于响应报文中,存放响应的信息,如资源的位置,服务器等;
- 实体首部,仅用于描述所数据的信息,即描述 HTTP 报文中
Entity Body部分,如数据长度、类型等。
通用首部
| 常见首部 | 描述 |
|---|---|
| Date | HTTP 响应创建的时间和日期 |
| Cache-Control | 用于控制缓存机制,作用在请求或者响应中,作用是单一方向的,请求和响应中的缓存控制各不相干 |
| Connection | 是否建立可持续连接 |
请求首部
| 常见首部 | 描述 |
|---|---|
| Accept | 说明客户端能接收的内容类型,多个类型用逗号隔开,类型格式:type/subtype;parameter=value |
| Accept-* | 说明客户端能接收的字符集、编码、语言等。Accept-Charset、Accept-Encoding、Accept-Language |
| Cookie | 存放服务端发送给客户端的 HTTP Cookie |
| Host | 所请求的服务器的域名 |
| User-Agent | 用户代理,标识客户端使用的应用、系统等信息 |
| Referer | 存放打开当前页面的源地址,方便服务端识别访问来源 |
| If-* | 条件请求,满足条件是请求才会成功,如 If-Match、If-Modified-Since、If-None-Match、If-Range、If-Unmodified-Since |
响应首部
| 常见首部 | 描述 |
|---|---|
| Age | 响应在代理缓存中存放的时间,以秒为单位,值为代理和通用首部 Date时间之差,为 0 值说明很有可能从服务器中获取 |
| Location | 说明资源重定向后的地址 |
| Server | 原始服务器使用的软件名称,如 Server: Apache/2.4.1 (Unix) |
| Allow | 声明请求资源可以使用的 HTTP 方法,如 Allow: GET, POST, HEAD,当响应的状态码为 405时必须带这个响应首部 |
实体首部
| 常见首部 | 描述 |
|---|---|
| Content-Length | 数据长度,整个 Entity Body 的字节数 |
| Content-Language | 数据显示时使用的语言,如 Content-Language: en,zh |
| Content-Encoding | 数据的压缩编码方式,如 Content-Encoding: gzip |
| Content-Type | 数据的 MIME 类型,如 Content-Type: text/html; charset=utf-8 |
| Content-Location | 说明资源的一个可用地址,服务器上的资源通常会有多个版本的地址,如一个资源可能存放在 json、text 或者 csv 文件中,根据客户端能接受的数据类型,返回相应的资源,下次请求时可以直接使用 Content-Location提供的资源路径,如Content-Location: /documents/foo.json |
HTTP 响应的状态码
| 类型 | 常见状态码 |
|---|---|
| 1xx:信息 | 100 Continue 101 Switching Proctocols |
| 2xx:成功 | 200 OK:请求成功 201 Created:请求成功同时资源在服务器中创建 202 Accepted:请求已接受,但尚未处理完 |
| 3xx:重定向 | 301 Moved Permanently:页面永久转移到新 url 302 Moved Temporarily:页面临时转移到新 url |
| 4xx:客户端错误 | 400 Bad Request:服务器不理解请求 401 Unauthorized:被请求的页面需要用户名和密码。 403 Forbidden:页面禁止访问 404 Not Found:没有找到请求的资源 405 Method Not Allowed:请求方法不被允许 |
| 5xx:服务器错误 | 500 Internal Server Error:请求未完成。服务器遇到不可预知的情况。 502 Bad Gateway:请求未完成。服务器从上游服务器收到一个无效的响应。 503 Service Unavailable:请求未完成,服务器临时过载或宕机。 504 Gateway Timeout:网关超时。 |
潜在的安全问题
页面处理:
- 输入内容不做过滤
- 不检查地址来源
- 输出内容不作处理
DNS 解析:
- 域名服务器被劫持(可能性很小)
- DNS 缓存投毒
参考
- Computer Networking A Top-Down Approach 6th Edition
- Web页面的请求历程
- HTTP tutorial
- How browser work
- DNS域名解析过程

